Voice cloning is marketed as a faithful copy of someone's voice. Across three widely used systems — ElevenLabs V3, Coqui-XTTS, and Chatterbox — we find that cloning is closer to style transfer: it systematically reshapes voices to sound warmer, more authoritative, more native-English, and more "humanlike" than the originals — and listeners trust the cloned voices more.

Listen for yourself
Each pair below contains a source recording from a non-native English speaker and a clone generated from that speaker's voice. Pay attention to accent.
Five things we found
- Finding 1 · Style shift Clones are rated more authoritative (+19%), more warm (+14%), more customer-service-like (+20%), and more humanlike (+14%) than the source recordings they came from.
- Finding 2 · Trust shift Annotators report higher trust in cloned voices (+18%) and are more willing to have an intimate conversation with the clone (+17%) than with the original speaker.
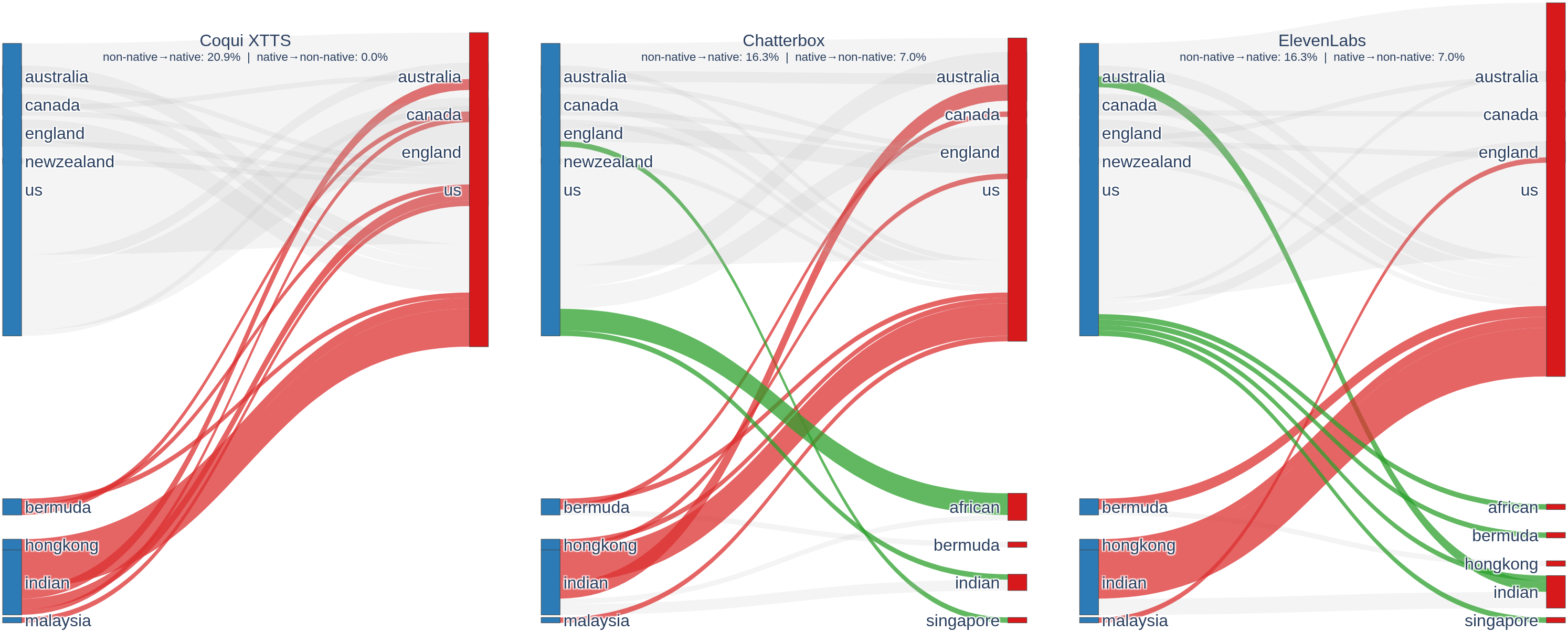
- Finding 3 · Accent homogenization Source speakers come from 22 language backgrounds. Their clones are pulled toward dominant Anglophone varieties: US, UK, Canadian, Australian, NZ. Native-English rating jumps +33%.
- Finding 4 · Identity collapse A speaker-identity classifier reaches 85% accuracy on sources but only 41% on clones — a 52% drop. Cross-sex misidentification roughly doubles. Speakers become harder to tell apart.
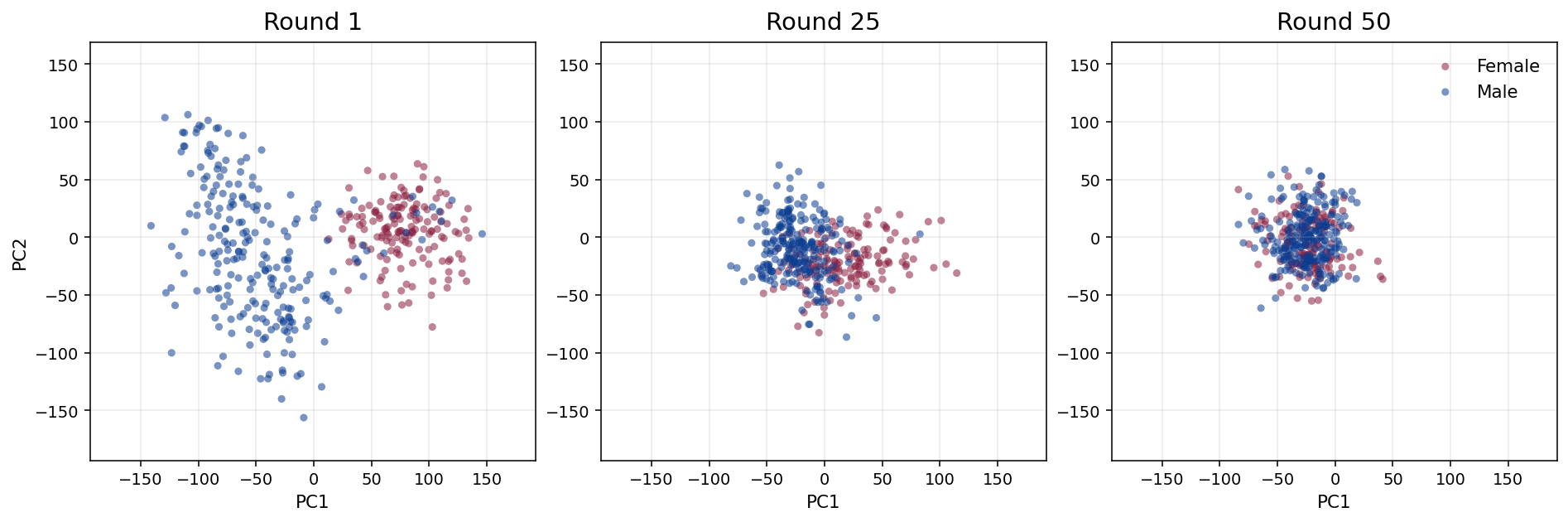
- Finding 5 · Iterative drift & convergence Cloning a clone, 50 times over, produces directional drift: pitch climbs, cosine similarity to the source collapses from 0.65 to 0.15, and embeddings cluster together. The "style" is convergent.
The x-axis is the standard 1–5 Likert response scale. E.g., a +20% shift on customer-service-likeness moves the average from roughly "slightly" to between "slightly" and "moderately".
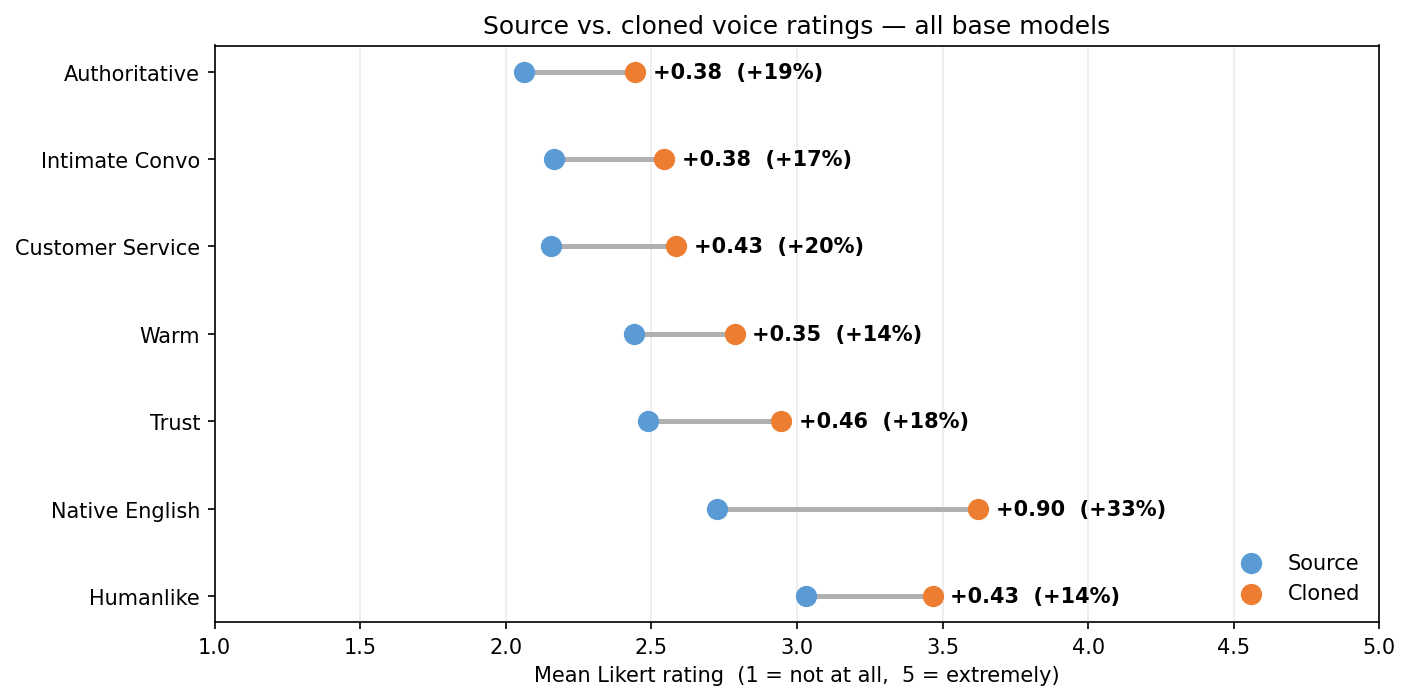
Cloned voices are rated more humanlike than the humans they were cloned from — a speech analogue of the hyperrealism seen in AI-generated faces (Miller et al., 2023).
Why this matters
The well-documented harms of voice cloning — non-consensual impersonation, voice-phishing scams, fraud against family members and businesses — are real and growing, and nothing in this work should be read as discounting them. Our findings sit alongside that record, not in place of it: even when a clone is generated with a speaker's consent for an identity-preserving use, it still doesn't sound like them.
For users who want to preserve their voice
Voice cloning is increasingly used in identity-preserving applications — finishing a recording, dubbing across languages, or restoring speech for someone who has lost theirs. In all of these settings, fidelity is the whole point. If the clone quietly removes a speaker's accent or smooths their cadence into a customer-service register, the technology is failing at its stated job.
For everyone who hears a cloned voice
Listeners trust cloned voices more than the originals, and report being more willing to disclose personal information to them. As synthetic voices show up in customer service, claims processing, and increasingly in scam calls, that asymmetry is a behavioral safety story, not just an aesthetic one.
For cultural diversity
The homogenization isn't random — it points at a specific prototype: fluent, "Standard" English, often Anglophone. The Sankey diagram below shows source accents on the left and the classifier's read of the cloned voice on the right. Coqui-XTTS pulls every speaker into one of the five Anglophone varieties (US, UK, Canadian, Australian, or New Zealand English).
What happens if you clone a clone?
We took each speaker's audio and ran 50 rounds of iterative cloning with Chatterbox. If cloning were faithful, the recordings should hover near the source. Instead, embeddings drift in a consistent direction, then converge into a single cluster — pitch climbs, similarity to the original collapses, and male and female speakers end up indistinguishable in embedding space.
How we did it
We recruited 86 non-native English speakers via Prolific (sex-balanced, ages 19–64, self-reported accent strength 0–10) and asked them to read the Grandfather Passage — a nine-sentence standard text used in speech assessment. We split each recording into sentence-level clips, quality-checked them, and used cross-sentence cloning: the model gets sentence ℓ as reference and is asked to produce sentence ℓ+1, so it must extract generalizable speaker features rather than copy phonetic content.
Annotators were monolingual US English speakers recruited via Prolific. Each session shuffled 10 source and 10 cloned clips from one model and one speaker-sex, so annotators were blind to which clips were human. We collected 4,000 paired annotations from 177 annotators.
The paper, the data, the code
Paper: https://arxiv.org/abs/2605.16578
Code: github.com/kzhou-cloud/voice-cloning-public
Dataset: huggingface.co/datasets/kzhou/voice_cloning_style_transfer
Cite this work
@article{zhou2026voicecloning,
title = {Voice "Cloning" is Style Transfer},
author = {Zhou, Kaitlyn and Bianchi, Federico and Bartelds, Martijn
and Pot, Anna and Kwon, Yongchan and Zou, James},
year = {2026},
note = {Preprint}
}